階層的なデータベースは...モデル、例
階層型データベースは、ツリー構造。構成原理により、コンピュータファイルシステムに多少似ています。このようなモデルの使用には、長所と短所があります。詳細については、この記事で説明します。
データベースの種類

ご存じのように、データベース遡及には4つのタイプがあります:
- リレーショナル表DBMS。情報は行の形式で表示されます。この原則によって、データベースは例えば「アクセス」で構築される。
- オブジェクト指向 - OOPと密接に関連(プログラミング、オブジェクトのある作品があります)、これは彼らの主なプラスですが、小さなパフォーマンスを考えれば、依然としてリレーショナルの蔓延よりもかなり劣っています。
- ハイブリッド - 上記の種のうちの2つを一度に収容できるDBMS。
- 階層的 - この記事の注目の対象。これは、ツリー構造によって特徴付けられるデータベースです。
階層的な基盤の最も有名な例データは、IMSと略される情報管理システム(「管理情報システム」と解釈される)と呼ばれる、IBMによって作成された製品(「IBC」)です。 IMSの最初のバージョンは、20世紀の六十八年に過去にリリースされました。今日のデータの保存と制御に使用されます。
階層モデル構築の原則

階層データモデルは、以下の原則に基づいています。
- ツリー構造の各ノードについて、あるセグメントが割り当てられる。
- セグメントとは、各フィールドに割り当てられ、1つの線形タプル内に配置された名前を有するデータフィールドを意味する。
- 1つ以上の一致:各入力フィールドに対して1つの入力セグメントと複数の出力セグメント。
- 各構造要素に対して、階層システムには1つの唯一の場所があります。
- ツリー構造はルート要素で始まります。
- 各従属ノードには祖先が1つしかありませんが、各ソースにはいくつかの子孫があります。
階層的なデータ構造の適用
階層型データベースは、最初にツリー構造によって特徴付けられるシステムに適用可能なリポジトリです。それらのために、そのようなシミュレーションの選択は論理的です。
最初から階層データベースの例体系的な程度 - あなたが知っているように、ランクを明確に定義している軍事単位。また、粒子の階層構造の底部まで単純化された複雑なメカニズムでもあります。このようなシステムをシミュレートし、それらを問題のデータベースの形式にするために、分解する必要はありません。しかし、このような状況は必ずしも当てはまりません。
さらに、下向きのクエリが同様の上向きのクエリよりも単純な傾向があります。
階層モデルを基盤とする基本的なデータベース操作
階層的なデータベース構造により、(スキルと能力に応じて)以下の操作を実行することができます(最も基本的なものが提示されていますが、リストはマイナーな追加で常に拡張できます)。
- アイテムのデータベースを検索する。
- ツリーからツリーまでデータベースを通過します。
- 木の上を動く - 枝から枝へ。
- 従って、枝に沿った遷移は要素単位である。
- レコードの操作:新規レコードの挿入、現在のレコードの削除、コピー、カットなど
構造の要約
構造を記述する「木」という用語すでにこの記事で2回以上言及されています。それはどこから来たのかを伝える時間です。階層型データベースはデータ型 "ツリー"を使用するデータベースなので、すべてです。彼が何であるかをもっと詳しく考えてみましょう。
これは複合型です: 要素(ノード)のそれぞれには、いくつかの後続の要素(1つ以上)があります。そして、それはすべて1つのルート要素で始まります。一番下の行は、タイプ "ツリー"の各部分がサブタイプであり、 "ツリー"であるということです。多くの、多くの枝分かれした、そしてすべての順序付けられた構造。
基本的なタイプはシンプルで複雑なものもありますが、基本的には常にレコードです。しかし、単純なレコードには1種類のデータがあり、複合データには1セットのデータがあります。
階層的モデルは原則に特有のものです各前のセグメントが次のセグメントの祖先であるときは子孫になります。さらに、上位型の子孫は従属型であり、互いに等価なエントリは双子型とみなされます。
DB充てん
階層データベースの主なデータは、レコードに格納される値(数値または記号)です。このようなデータベースは、通常、下から上、左から右に渡されます。
利点
階層データベースは、ルートを持つデータベースですデータベースフォルダー、徐々に分岐します。このような構造がファイルシステムと非常に似ていることを考えると、そのようなデータベースはコンピュータデータに対する様々な操作を実行するために首尾よく使用される。結果:彼女の記憶の合理的な分布だけでなく、仕事に費やされた時間の非常にまともな指標。

階層モデルは、順序付けられた情報に適用するのに理想的です。
短所
しかし、考慮されているDBMSの同じ機能、彼らの主な利点となった、また彼らの欠点を決定する。たとえば、経験豊かなスペシャリストが以前は知られていないベースで作業することは難しく、シンプルなユーザーはその中で「迷子になる」という論理的な接続の嵩高さと複雑さです。このような理解の複雑さは、実際には階層的モデル上に実際に構築されるDBMSはほとんどないという事実につながります。階層型データベースの例としては、IBEEM、Oka、MIRIS(ロシア製)、Data Edge、Team-UP(海外企業)などの製品に加えて、
例
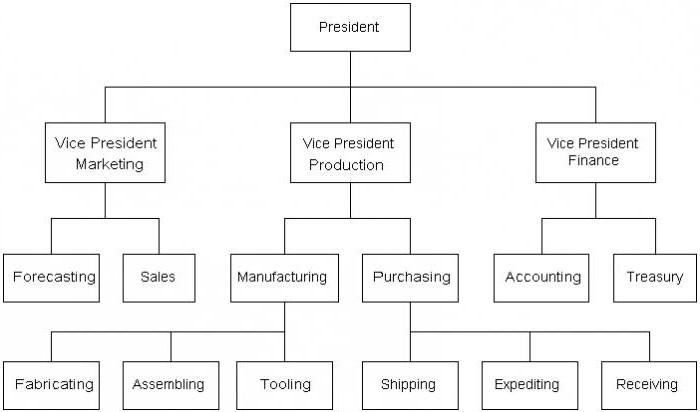
階層型データベースは多様です関係が構築される異なるレベル。概略的には、反転グラフのように見えます。階層型データベースの例としては、州政府の管理機関があります。学校を考えましょう。

最高レベルに位置します行政の「リーダー」はディレクターです。彼の服従は頭の先生であり、頭の先生は先生であり、クラスの並行を監督しています。それぞれは無制限に並行していて、各クラスには一定数の学生がいます。
同じ原理で描くことができますどの企業の管理。同社の取締役または取締役会が一番上にあります。それから、ユニットの数が増え、それぞれに独自の構造があります。共通の特徴があります:各部門長、補佐官、幹事、事務所スタッフなどです。
コンピュータアプリケーション
もっと深刻な用途があるかもしれません。 階層型データベースの最も重要な例は、ファイルシステムです。使い慣れた「エクスプローラ」は、他の多くのファイルマネージャと同様に、このスキームに従って「Windows」オペレーティングシステムの中核となるすべての人のために構築されています。
ネットワークデータベース
そこには:
- リレーショナル;
- 階層的;
- ネットワークデータベース。
なぜ我々は再び分類を覚えたのですか?リレーショナルとは異なり、ネットワークデータベースには同様の階層的機能があるためです。
データベースの関係の種類を覚えておく時間。 1対1、1対多、多対多のリンクがあります。私たちは後者に興味があります。ネットワークデータベースでは、以下のようにそれ自身が現れます。単一の相続人ノードは、一度に複数の祖先を持つことができます。複数の子供を持つという性質も保持されています。階層的なデータベース、ネットワークデータベースそのものがそのような継承の例であると言えるでしょう。この場合、ネットワークデータベースの構造構築の原則は同じままであるため、祖先は正確に階層データベースです。
階層と関係性
「リレーショナル」という名前は英語から来ます「態度」という言葉。記事の冒頭で述べたように、それらはしばしば表で表されます。しかし、前の段落では、階層データベースが接続を構成することができることを示しました。これは、これらの2つのタイプの間にいくつかの細いスレッドがあることを意味していますか?

はい。 第1のタイプと第2のタイプの両方が依然としてデータベースに関連しているという事実に加えて、この機能に加えてもう1つ共通の特性があります。たとえば、階層データベース(およびそれに伴うネットワーク)を表で表現することができます。ここでのポイントは、エンドユーザーに情報を提示する形式ではありません(これはすでにインターフェイスのユーザビリティの問題です)。したがって、部門、部門、およびその他の部門との明確な部門は、階層内で引き続き表現されますが、便宜上、表に記載されています。



